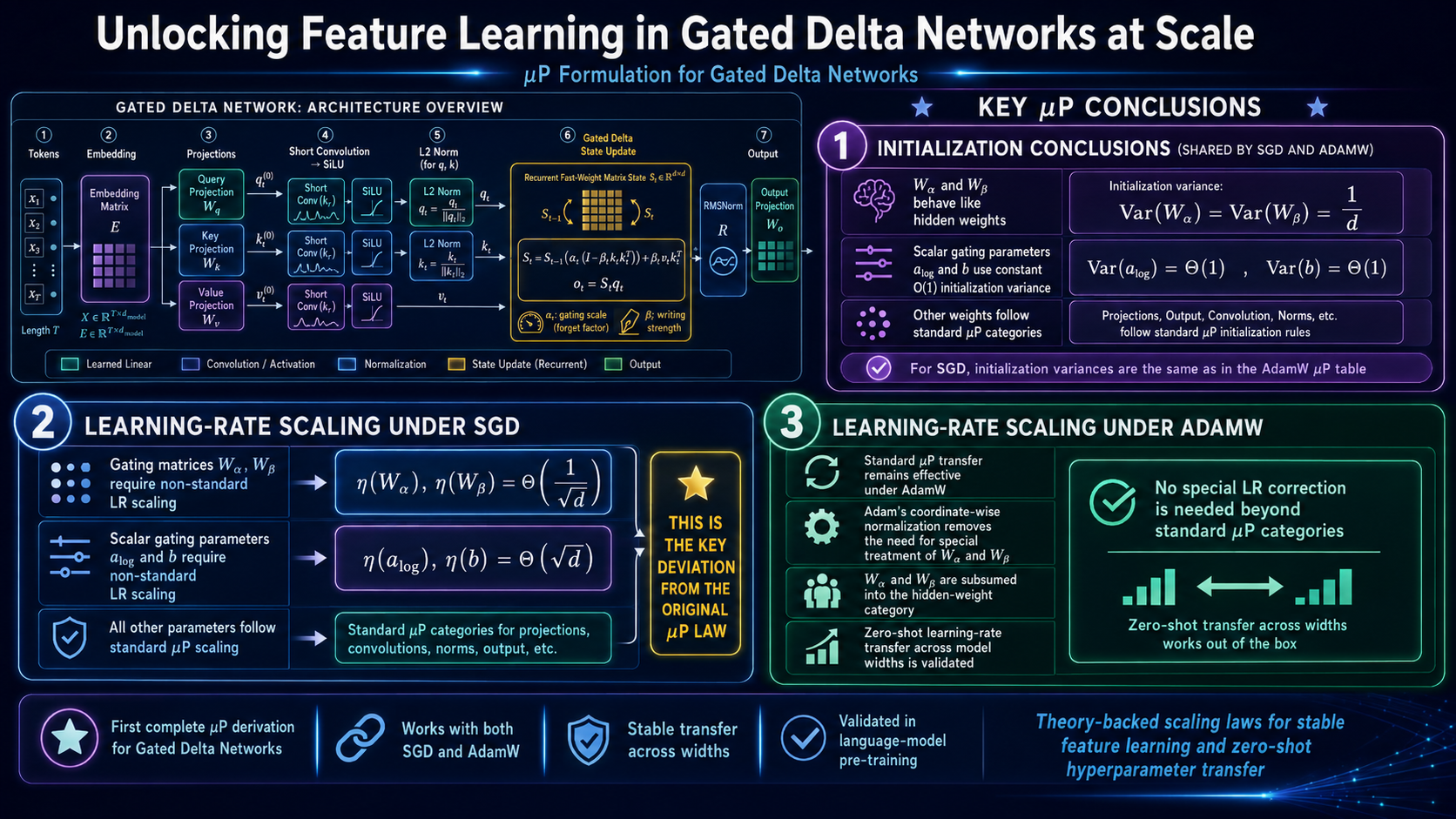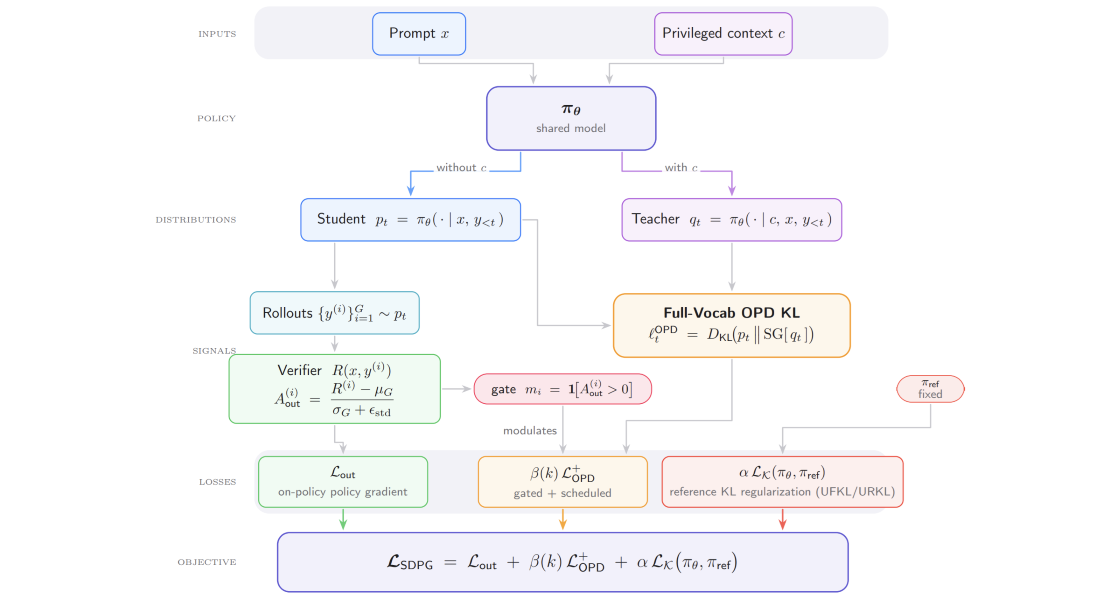
Self-Distilled Policy Gradient
Self-Distilled Policy Gradient
“在线策略自蒸馏”(On-policy self-distillation)是一种极具潜力的密集监督来源,尤其适用于稀疏奖励强化学习场景;在该机制下,语言模型会基于一种“特权上下文”(privileged context)来对其自身的生成内容进行监督。
具体而言,这一机制可被实例化为一种辅助性的、基于全词汇表的“学生-教师”逆向 Kullback-Leibler(KL)散度损失。鉴于此,我们提出了一种名为 SDPG 的自蒸馏策略梯度框架。
该框架融合了“组相对验证器优势”(group-relative verifier advantages)与归一化标准差、精确的全词汇表在策略自蒸馏,以及参考策略 KL 正则化技术。
实证结果表明,相比于 RLVR 算法及各类自蒸馏基线模型,SDPG 在训练稳定性和性能方面均实现了显著提升。
On-policy self-distillation, where a language model conditions on privileged context to supervise its own generations, is a promising source of dense supervision for sparse-reward reinforcement learning.
Actually, it can be instantiated as an auxiliary full-vocabulary student-to-teacher reverse Kullback-Leibler divergence loss.
We therefore propose SDPG, a self-distilled policy-gradient framework that combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation, as well as reference-policy KL regularization.
Empirically, SDPG improves stability and performance over RLVR and self-distillation baselines.