T-Rex
T-Rex
作为计算化学中的一项基本任务,逆向合成预测旨在识别一组反应物来合成目标分子。现有的无模板方法只考虑目标分子的图结构,通常不能很好地推广到稀有反应类型和大分子。
在这里,我们提出了T-Rex,这是一种文本辅助逆转录合成预测方法,它利用预先训练的文本语言模型,如ChatGPT,来帮助生成反应物。
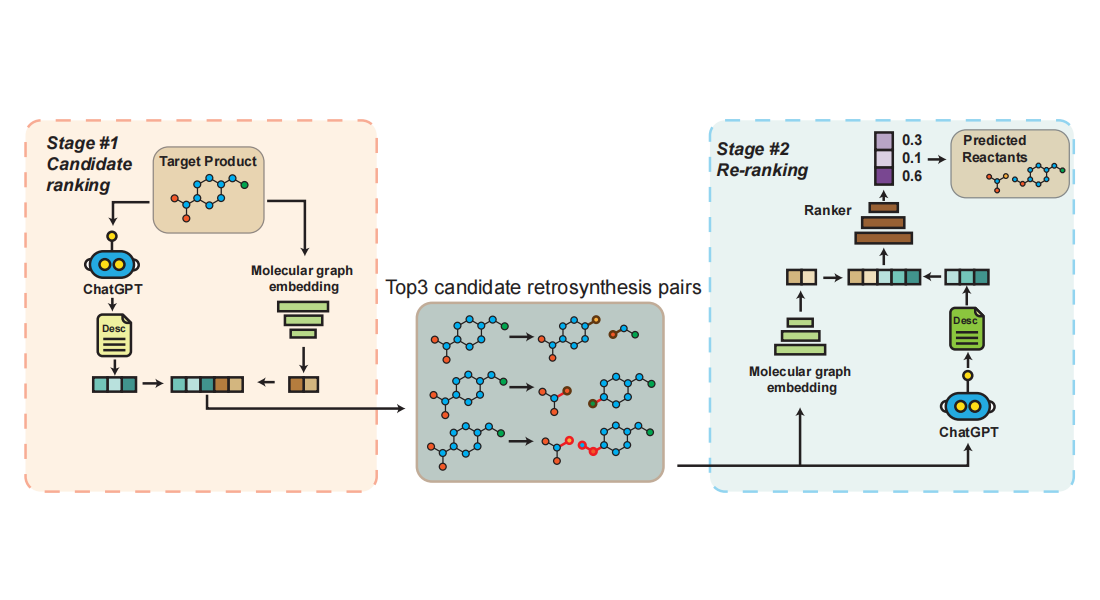
T-Rex首先利用ChatGPT生成目标分子的描述,并根据描述和分子图对候选反应中心进行排名。
然后,它通过查询每种反应物的描述对这些候选者进行重新排序,并检查哪组反应物最能合成目标分子。
我们观察到,T-Rex在两个数据集上的表现明显优于基于图的最先进方法,这表明了考虑文本信息的有效性。
我们进一步发现,T-Rex的表现优于仅使用基于ChatGPT的描述而没有重新排序步骤的变体,这表明我们的框架如何优于ChatGPT和图形信息的直接集成。
总的来说,我们表明,由预先训练的语言模型生成的文本可以显著改善逆向合成预测,为利用ChatGPT来推进计算化学开辟了新的途径。
As a fundamental task in computational chemistry, retrosynthesis prediction aims to identify a set of reactants to
synthesize a target molecule. Existing template-free approaches only consider the graph structures of the target
molecule, which often cannot generalize well to rare reaction types and large molecules. Here, we propose T-Rex, a
text-assisted retrosynthesis prediction approach that exploits pre-trained text language models, such as ChatGPT,
to
assist the generation of reactants. T-Rex first exploits ChatGPT to generate a description for the target molecule
and
rank candidate reaction centers based both the description and the molecular graph. It then re-ranks these
candidates by
querying the descriptions for each reactants and examines which group of reactants can best synthesize the target
molecule. We observed that T-Rex substantially outperformed graph-based state-of-the-art approaches on two
datasets,
indicating the effectiveness of considering text information. We further found that T-Rex outperformed the variant
that
only use ChatGPT-based description without the re-ranking step, demonstrate how our framework outperformed a
straightforward integration of ChatGPT and graph information. Collectively, we show that text generated by
pre-trained
language models can substantially improve retrosynthesis prediction, opening up new avenues for exploiting ChatGPT
to
advance computational chemistry.