Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1.5: Scaling Reinforcement Learning with LLMs
具有后续标记预测的语言模型预训练已被证明其尺度定律是有效的,但受到可用训练数据量的限制。
扩展强化学习为人工智能的持续改进开辟了一条新的方向,并预示大型语言模型可以通过学习探索并获得奖励来扩展其训练数据。
然而,之前发表的研究并没有产生具有竞争力的结果。有鉴于此,我们报告了Kimi k1.5的培训实践,这是我们最新的多模态LLM,采用RL进行培训,包括其RL培训技术、多模态数据配方和基础设施优化。
长上下文扩展和改进的策略优化方法是我们方法的关键组成部分,它建立了一个简单、有效的RL框架,而不依赖于蒙特卡洛树搜索、值函数和过程奖励模型等更复杂的技术。
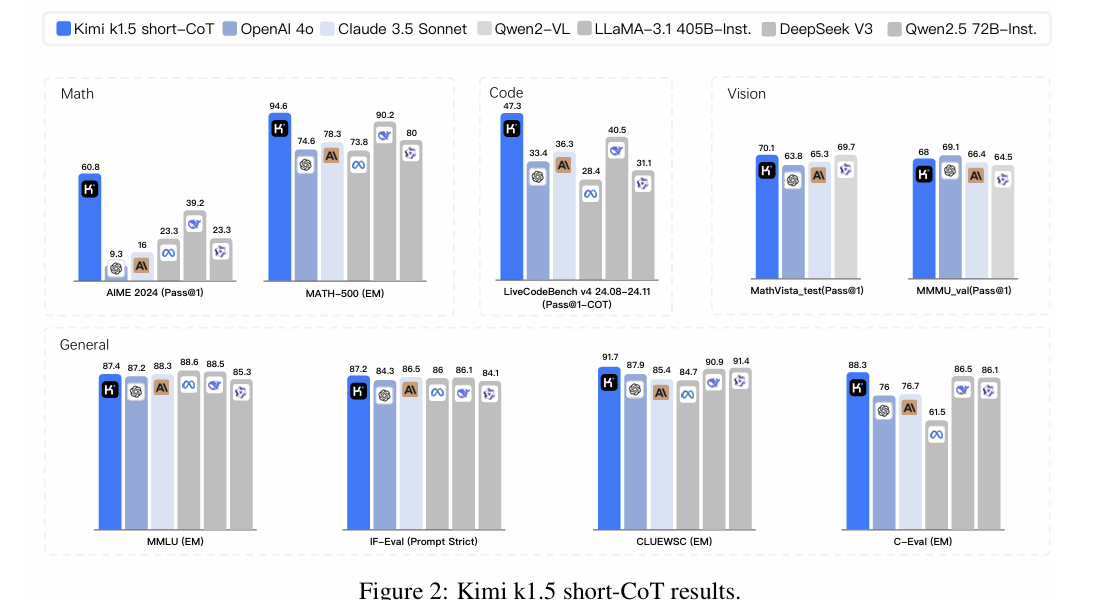
值得注意的是,我们的系统在多个基准和模式上实现了最先进的推理性能———例如,在AIME上为77.5,在MATH 500上为96.2,在Codeforce上为94百分位数,在MathVista上为74.9——与OpenAI的o1相媲美。
此外,我们提出了有效的long2short方法,该方法使用长CoT技术来改进短CoT模型,产生了最先进的短CoT推理结果——例如,在AIME上为60.8,在MATH500上为94.6,在LiveCodeBench上为47.3——大大优于GPT-4o和Claude Sonnet 3.5等现有的短CoT模型(高达+550%)。
Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data.
Scaling reinforcement learning (RL) unlocks a new axis for the continued improvement of artificial intelligence, with the promise that large language models (LLMs) can scale their training data by learning to explore with rewards.
However, prior published work has not produced competitive results. In light of this, we report on the training practice of Kimi k1.5, our latest multi-modal LLM trained with RL, including its RL training techniques, multi-modal data recipes, and infrastructure optimization.
Long context scaling and improved policy optimization methods are key ingredients of our approach, which establishes a simplistic, effective RL framework without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models.
Notably, our system achieves state-of-the-art reasoning performance across multiple benchmarks and modalities -- e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista -- matching OpenAI's o1.
Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models, yielding state-of-the-art short-CoT reasoning results -- e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench -- outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%).